
Written By: Sudeshna Ghosh
Table of Contents
Highlights of the Case Study
| Serial No | Topic |
|---|---|
| 1. | Introduction to ETL Optimization |
| 2. | Quantzig’s Expertise in ETL Optimization Solution for a UK-Based Financial Institution |
| 3. | Importance of ETL Optimization in Modern Data Management |
| 4. | How is ETL Optimization Enhancing Performance and Efficiency Across Industries? |
| 5. | Realizing the Full Potential of ETL Optimization for Business Success |
| 6. | Conclusion |
Introduction to ETL Optimization
ETL is the systematic approach that combines large amounts of data from multiple sources into a centralized repository, typically a data warehouse. Utilizing a range of ETL tools and processes, this method applies a set of business rules to organize, clean, and prepare raw data for crucial tasks like data analytics, storage, and machine learning (ML) applications. Whether you’re doing a BI engineer job, data analyst, ETL developer, or data engineer, a deep understanding of ETL’s varied applications and use cases is vital. It enables you to maximize data utility, unlocking the capabilities and power of ETL in your organization. This article aims to explore the diverse use cases of ETL and illustrate its critical role in achieving success in data-driven enterprises.
Book a demo to experience the meaningful insights we derive from data through our analytical tools and platform capabilities. Schedule a demo today!
Request a Free Demo
Quantzig’s Expertise in ETL Transformation Solution for a UK-Based Financial Institution
| Category | Details |
|---|---|
| Client Details | A prominent financial institution based in the UK, known for its expansive data operations and critical decision-making processes. |
| Challenges Faced by The Client | Our client was facing several challenges with high response time of current tools, lack of scalability, and high manual maintenance costs. |
| Solutions Offered by Quantzig | Quantzig’s innovative solutions involved microservices architecture for ETL frameworks, optimization of data schema, and automated data quality governance frameworks. |
| Impact Delivered | 70% higher performance of reporting tools, incorporation of 50+ new solutions without scaling architecture, and 60% reduction in manual dependency. |
Client Details
We partnered with a prominent financial institution based in the UK, known for its expansive data operations and critical decision-making processes.
Challenges Faced by the Client
The client encountered several major challenges:
- High Response Time of Current Tools: The existing tools were slow in data retrieval and analysis, leading to prolonged decision-making processes, reduced operational efficiency, and hindered employee productivity.
- Lack of Scalability: The client’s technology infrastructure struggled to accommodate increased data demands, leading to performance degradation, slower response times, and occasional system crashes.
- High Manual Maintenance Costs: Extensive manual interventions in data maintenance were draining resources, leading to increased errors and compromising data integrity.
Solutions Offered by Quantzig
- Microservices Architecture for ETL Frameworks: We introduced a microservices architecture to create reusable, scalable ETL frameworks. This modular approach allowed for independent development and maintenance of ETL components, enhancing flexibility and efficiency in data processing.
- Optimization of Data Schema: Transitioning from a de-normalized to a star schema simplified the data structure, enhancing query performance, reducing redundancy, and streamlining data integration.
- Automated Data Quality Governance Frameworks: Implementation of automated frameworks enabled real-time monitoring of data quality, improved accuracy through automated profiling and cleansing, and facilitated accountability and transparency in line with governance requirements.
Impact Delivered from Quantzig’s ETL Transformation Solution
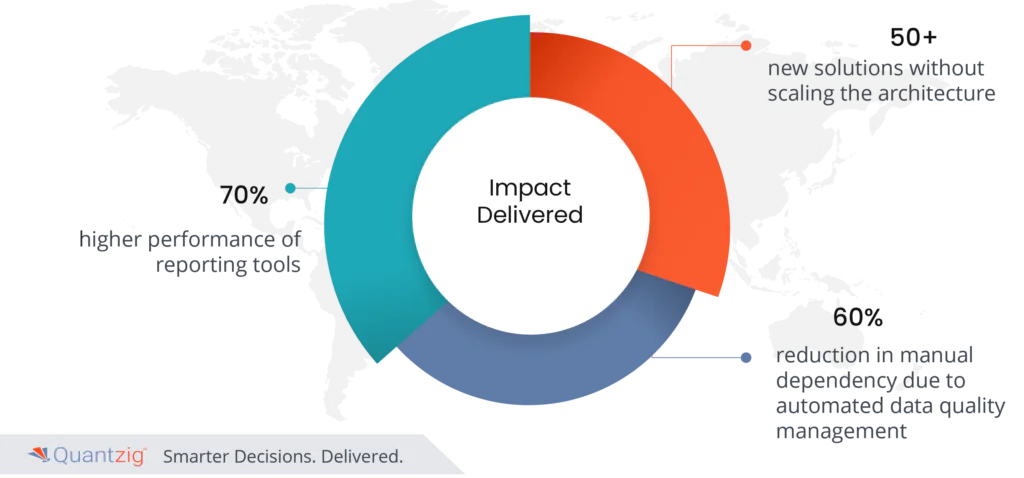
- 70% Higher Performance of Reporting Tools: The optimized ETL process significantly improved the performance of reporting tools, enabling faster and more efficient data analysis.
- Incorporation of 50+ New Solutions Without Scaling Architecture: The scalable ETL frameworks allowed for the addition of over 50 new solutions without the need for architectural scaling.
- 60% Reduction in Manual Dependency: Automated data quality management significantly reduced manual intervention, enhancing efficiency and reducing the likelihood of errors.
Get started with your complimentary trial today and delve into our platform without any obligations. Explore our wide range of customized, consumption driven analytical solutions services built across the analytical maturity levels.
Start your Free Trial TodayImportance of Extraction Transformation Loading Process Optimization in Modern Data Management
By refining ETL processes, organizations can enhance their Data Warehouse capabilities, resulting in superior Data Quality and validation. Implementing ETL best practices in Data Transformation and Loading streamlines Data Pipelines and supports robust Data Engineering. This leads to improved performance optimization and effective Data Management, integrating seamlessly with CRM systems. Additionally, an optimized ETL framework feeds accurate and timely data into interactive dashboards and maintains a dependable Data Repository, ultimately driving better decision-making and operational efficiency.
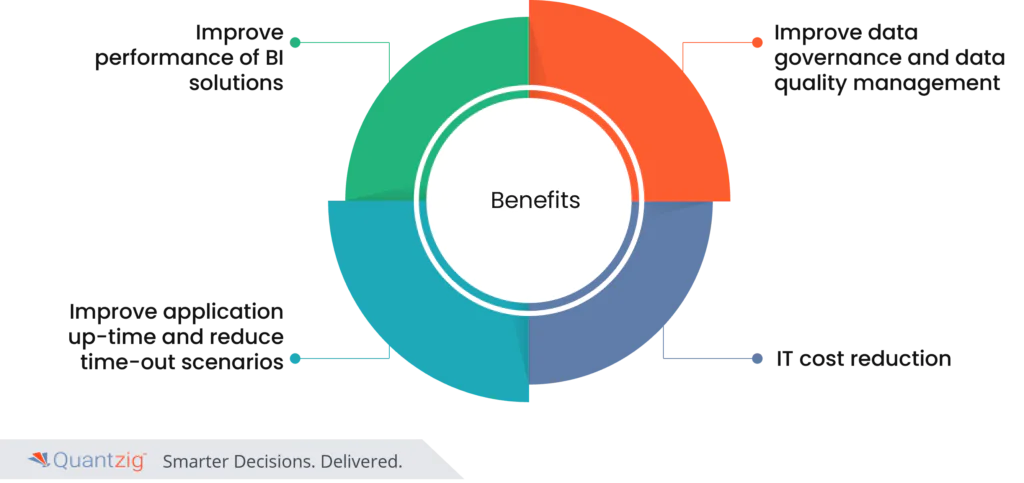
1. Improve performance of BI Solutions
ETL optimization is pivotal in boosting the performance of Business Intelligence (BI) solutions. In today’s digital age, enterprises rely heavily on vast volumes of datasets to sharpen their decision-making and gain deeper business insights. ETL optimization enhances the accuracy, detail, reliability, and efficiency of BI and analytics. It effectively aggregates data from diverse sources, transforming it into a consistent format before loading into a data warehouse. This results in a more comprehensive view of both recent and historical data, enabling in-depth reporting and analysis that ensures data reliability.
2. Improve application up-time and reduce time-out scenarios
ETL optimization also plays a crucial role in improving application up-time and reducing time-out scenarios. During extraction, ETL gathers up-to-date data from various sources. The transformation phase then normalizes, cleanses, and organizes this data, minimizing inconsistencies that could lead to application errors. By structuring data effectively, ETL reduces the likelihood of timeouts caused by poorly formatted inputs, enhancing the overall performance and reliability of applications.
3. Improve data governance and data quality management
Moreover, ETL optimization is essential for improving data governance and quality management. As organizations manage larger data stores and transfer significant information volumes to data warehouses, the risk of data breaches increases. ETL processes help implement effective data management policies and governance, complying with regulations like HIPAA, CCPA, GDPR, and SOC2. These processes are crucial for removing or encrypting sensitive data before transferring it to a data warehouse, aiding in regulatory compliance and ensuring data transparency and security.
4. IT cost reduction
Lastly, ETL optimization contributes to significant IT cost reduction. By minimizing data transfer and processing times, it alleviates the strain on network and hardware resources. Efficient transformations and automated workflows reduce manual intervention and labor costs. Additionally, data accuracy and consistency, achieved through optimized ETL, reduce the likelihood of costly errors and rework, translating into direct IT infrastructure, labor, and operational cost savings.
How is Extraction Transformation Loading Process Optimization Enhancing Performance and Efficiency Across Industries?
ETL optimization stands at the forefront of operational excellence and informed decision-making in our dynamic landscape. Its applications are vast and varied, spanning across multiple industries such as finance, healthcare, e-commerce, and beyond. By integrating disparate data sources, ETL optimization empowers organizations to fully harness their data assets, leading to improved data governance, quality, and accessibility.
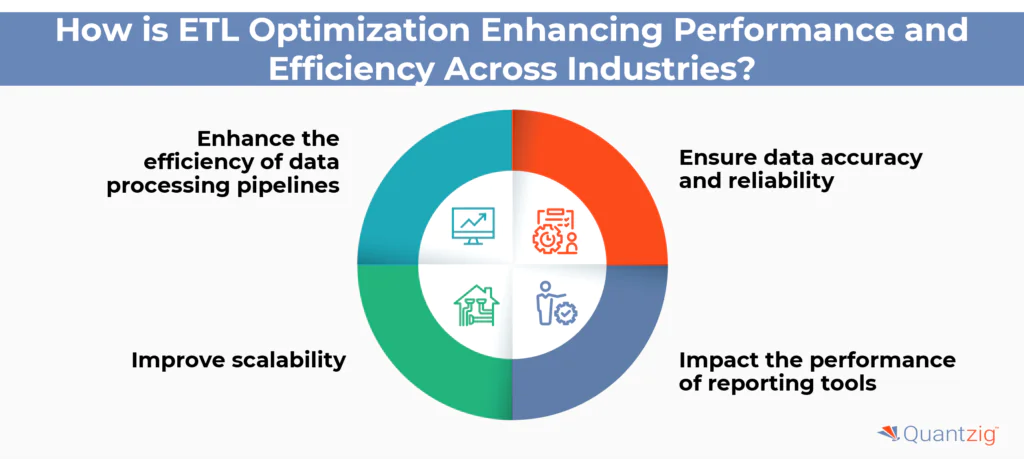
1. Enhance the efficiency of data processing pipelines
One of the key use cases of ETL optimization is in enhancing the efficiency of data processing pipelines. Techniques like parallel processing, data partitioning, and schema optimization (such as transitioning from a de-normalized to a star schema) are employed to boost ETL operations. These strategies enable faster data processing, reduced overhead, and improved throughput. Identifying and eliminating unnecessary data transformations is a crucial part of this process, aiming to minimize resource usage and streamline workflows.
2. Ensure data accuracy and reliability
Furthermore, ETL optimization plays a significant role in ensuring data accuracy and reliability. It involves the implementation of automated data quality governance frameworks, which facilitate real-time monitoring of data quality metrics. Automated profiling and cleansing routines are integral to this process, ensuring the decision-making insights are based on accurate and reliable data.
3. Improve scalability
Another vital aspect of ETL optimization is scalability. It includes adopting architectures like microservices to create reusable ETL frameworks, allowing for increased adaptability and agility in handling data. This approach is particularly beneficial for organizations experiencing growth or seasonal spikes in data, enabling them to scale up their ETL processes efficiently without performance degradation.
4. Impact the performance of reporting tools
Additionally, ETL optimization significantly impacts the performance of reporting tools. By incorporating advanced techniques like indexing, SQL tuning, and query optimization, ETL processes can be made more efficient, leading to a 70% improvement in reporting tool performance. This optimization is also crucial for integrating new solutions into existing architectures without the need for scaling, thus ensuring seamless data integration and analysis.
In a nutshell, ETL Optimization is significantly enhancing performance and efficiency across industries by refining ETL (Extract, Transform, Load) processes. This optimization ensures that Data Transformation and Loading are conducted seamlessly, which improves Data Quality and enables rigorous Data Validation. By adhering to ETL Best Practices, organizations can streamline Data Pipelines, bolstering their Warehouse capabilities. Enhanced ETL processes support robust Data Engineering and comprehensive Data Management, integrating effectively with CRM systems for better customer insights. Furthermore, performance optimization through ETL ensures that Interactive Dashboards and Data Repositories are accurate and up to date, facilitating informed decision-making and operational efficiency.
Realizing the Full Potential of ETL Optimization for Business Success

In the modern era where data is a key driver of business success, ETL optimization emerges as an indispensable catalyst. Its diverse use cases across various industries demonstrate its critical role in streamlining operations and enhancing decision-making. Through the strategic integration of disparate data sources, ETL optimization enables organizations to tap into the full potential of their data assets, leading to enhanced data governance, quality, and accessibility.
The core of ETL optimization lies in its ability to make data integration workflows more efficient and effective. Techniques like parallel processing, advanced compression algorithms, and optimized data schemas play a pivotal role in this transformation. They not only speed up data processing but also ensure data is loaded into target systems accurately and with minimal resource impact. The result is a significant reduction in data processing time, sometimes by up to 43%, and a notable average cost reduction of 21% in data integration processes.
By prioritizing ETL optimization, businesses achieve not only faster data loading speeds but also improved data accuracy and storage efficiency. This strategic approach is reflected in the enhanced performance of data loading and reporting tools, leading to more rapid and informed decision-making processes. With nearly 82% of businesses reporting improved data accuracy post-ETL optimization, it’s clear that these strategies are essential for any B2B organization.
In conclusion, ETL optimization is more than a technical process; it’s a strategic move towards operational excellence and business intelligence. Its impact on performance, efficiency, and cost reduction makes it a valuable tool for any organization looking to thrive in today’s data-centric world.
Experience the advantages firsthand by testing a customized complimentary pilot designed to address your specific requirements. Pilot studies are non-committal in nature.
Request a Free PilotConclusion:
ETL optimization is crucial for maintaining the efficiency and effectiveness of data processes in modern organizations. By enhancing ETL (Extract, Transform, Load) operations, businesses can ensure their Data Warehouse functions optimally, supporting robust Data Management and Data Engineering efforts. ETL best practices, including meticulous Data Transformation, Data Loading, and Validation, uphold Data Quality and streamline Data Pipelines. This optimization fosters performance optimization and seamless integration with CRM systems. Furthermore, interactive dashboards, fed by a well-maintained Data Repository, provide actionable insights, showcasing the critical role of optimized ETL processes in driving informed decision-making.


